
AI(LLM) Agent의 구성 요소

- Model: AI Agent의 두뇌에 해당하는 요소로, reasoning & decision-making을 담당하는 핵심 요소. 입력을 이해하고, 추론과 계획 및 생성 작업을 수행.
- Memory: 주로 단기 기억/장기 기억으로 구분.
- Planning: 하위 목표를 설정하거나, 피드백 수집 및 개선을 위한 요소.
- Tools: 외부 세계와 상호작용하기 위해 사용하는 도구. (ex. Web 검색, 메일 API, 스프레드시트, 계산/코딩 인터페이스)
- Orchestration layer: 전체 흐름을 제어하고 관리하는 핵심 요소. Agent Framework(LangChain, AutoGPT 등)에 해당.
- Instruction: AI Agent가 어떤 행동을 해야하는지에 대한 지침이나 규칙 (ex. 프롬프트)
- Runtime: AI Agent가 동작하는 실행환경으로, 모듈 요소들을 조합하고 흐름을 제어하는 시스템.

Model(LLM) & Instruction
- Prompt→ LLM-blackbox → Generation result
- 입력의 다양성 해결: In-context learning
- 입력에 따른 품질의 다양성 해결: Prompt engineering
- 모델 결과의 다양성 해결: 특정한 출력 형식에 맞추거나(pydantic 등으로 형식 정의), 제공한 tool schema에 맞추기.
Task complexity, Latency, Cost를 고려하여 Model 선택 (ex. 단순 검색 및 의도 분류는 더 작고 빠른 모델로)
Clear Instruction
- 명확하게 Agent의 actions / input&output / task 분담 & 설정
- Edge cases - real-world 상호작용에서 사용자가 불완전한 정보나 예상하지 못한 질문을 했을 때 decision point를 생성하는 것도 고려.
Memory
- Short-term memory(Working memory)
- 일반적으로 모델의 context window를 사용하여 prompt의 일부로 전체 대화 이력을 추적.
- Context window가 작은 모델이거나 대화 이력이 방대할 경우, 지금까지 진행된 대화를 요약하기 위해 다른 LLM을 사용할 수도 있음.
- Long-term memory
- 오랜 기간 동안 유지되어야 하는 Agent의 past action space & 여러 다른 세션에서 얻은 정보를 유지하는 것 포함.
- Long-term memory를 활성화하는 일반적인 기법: 이전 상호작용, 행동, 대화를 모두 외부 벡터 데이터베이스에 저장하기.
- ex) Cognitive Architectures for Language Agents (Sumers, Theodore, et al., TMLR, 23.09.)
- 메모리 + 행동(검색, 학습, 추론, 관찰, 행동) + 의사결정
- 장기 기억 → procedural(작업 흐름) / semantic(지식/사실 등 객관적 정보) / episodic(대화 내용)

- 인간의 기억을 참고한 Memory 분류

Planning
- 주어진 작업을 실행 가능한 단계들로 분할하는 과정으로, 이를 위한 여러 가지 기법들 존재.
- 일반적인 작업 분해 과정
- CoT: "Steps for XYZ.\\n1.” , "What are the subgoals for achieving XYZ?”
- 작업의 특성에 따른 분해 지시: "Write a story outline.”
- 사람이 직접 단계를 분해하여 입력.
-
- Reasoning: 복잡한 추론
- ReAct(Reason and Act): Action 지시 전까지 Thought와 Observation 반복
- Thought - 현재 상황에 대한 추론 단계
- Action - 실행해야 할 행동들(예: 툴 사용)
- Observation - 행동의 결과에 대한 추론 단계

- Reflecting(Reflexion): 언어적 강화(verbal reinforcement)를 통해 에이전트가 이전의 실패로부터 배우도록 돕는 기법
- 동적 Memory 모듈을 추가하여 action(단기)과 self-reflecting(장기)을 추적함으로써, Agent가 실수로부터 학습하고 개선된 행동을 찾도록 도움.
- 3가지 LLM role setting
- Actor: state observations에 기반해 행동을 선택하고 실행.
- Evaluator: Actor가 만든 출력물을 점수화.
- Self-reflection: Actor가 취한 행동과 Evaluator가 생성한 점수를 돌아보며(Reflecting) 평가.

- Chain of Hindsight(CoH; Liu et al. 2023): 피드백으로 주석이 달린 일련의 과거 출력을 명시적으로 제시함으로써 모델이 자체 출력을 개선하도록 함.
Tools
- Web 검색, DB 조회, API 연동까지 다양한 외부 인터페이스와 효율적 소통(action & orchestration)
- 모델에게 호출 요청 시 “사용 가능한 도구”의 명세(ex. JSON)를 함께 입력 → 실제 호출 후 결과 전달 및 생성.
- 외부 API 사용법을 배우기 위해(Tool Usage에 특화되기 위해) 모델을 Fine-tuning: TALM(Tool Augmented Language Models; Parisi et al. 2022)/Toolformer(Schick et al. 2023)
[ Tool의 대표적 형태 ]
(1) Extension: Agent가 직접 API 호출을 수행. LangChain에서 자주 사용되는 방식.
- 구현 방법
- API 정의: 사용할 외부 API의 엔드포인트, 매개변수, 응답 형식을 정의.
- 확장 구현: API 호출에 필요한 인증, 매개변수 설정, 응답 처리 등을 담당.
- 사용 예시 제공: Extension을 언제 어떻게 사용해야 할지 알 수 있도록, 명확한 예시를 prompt 형태로 제공.

(2) Function: 모델이 실행할 코드(함수명 + 인자값(JSON 형태))를 제안하고, 호출/실행은 클라이언트 쪽에서 담당.
- 유용한 경우: API 호출이 에이전트 아키텍처 흐름 외부에 필요한 경우, 보안/인증 제약으로 에이전트(Agent)가 직접 API를 호출할 수 없는 경우, API 호출 타이밍 또는 순서 제어가 필요한 경우, API 응답에 추가적인 데이터 변환 로직이 필요한 경우.
- 예시: 데이터 필터링 함수, 데이터 변환 함수, JSON 생성 함수.
- 구현 방법
- 함수 정의: 수행하고자 하는 작업을 명확히 정의.
- 함수 구현 및 도구화(tool로 등록)

(3) Data Stores: 외부 문서, 데이터베이스 등에서 실시간으로 정보(context)를 찾아주는 벡터 검색 기반 저장소 (RAG)
- 학습 데이터 외에 추가적인 정보(실시간 데이터 또는 대량의 데이터)에 접근 가능.
- 구현 방법: 데이터 수집 / 데이터 indexing / Retriever

AI(LLM) Agent의 디자인 패턴(아키텍처 설계)
AI(LLM) Agent를 구현하기 위해 고려해야할 요소들? Challenges?
- Goal + Tool + Feedback + Governance(제어,권한)
- LLM이 제공할 context & Agent의 전체 작업 흐름 관리(process 설계, workflow)
- Planning - 작업 처리 방식 / 작업 세분화, 각 단계마다 어떤 행동이 필요한지 계획.
- Reflection - 스스로 피드백 주고, 피드백 반영해 출력 재개선.
- Tool usage - 외부 api 호출, 코드 생성, 검색.
- Single-agent v/s Multi-agent collaboration
- Multi-agent collaboration: 보통 전문화된 Agent들로 구성되며, 각각 고유한 툴 세트를 보유하고 supervisor가 이를 감독하는 형태. Supervisor이 특화된 Agent들에게 tasks routing(role setting) → Agent들끼리 communication
- 2가지 주요 고려 사항
- Agent Initialization — 개별(전문화된) Agent들은 어떻게 생성되는가?
- Agent Orchestration — 모든 Agent들은 어떻게 조율되는가?
- 실제 Production Agent를 구현하기 위해 해결해야 할 Challenges
- Data(Knowledge): 지식 저장소의 효율적 구축 & 검색 필요.
- Data 적재 방법 및 기준, Indexing, 검색, 검색 후 post-processing.
- 신뢰 가능한 지식 knowledge 적재/추출 → 산재된 비정형, 비표준 format 통일화(ex. embedding)
- Data 적재/검색 과정의 최적화 필요(context length 한계 해결, 빠르게 실험/개선 가능한 파이프라인 구축)
- Evaluation: 전문가 지향의 고품질 생성에 대해 효과적으로 평가.
- 중간 생성 결과물 & Agent 행동에 대한 evaluation도 고려.
- Monitoring부터 시작하기 - LLM이 query에 대해 생성한 결과물을 기록 → 직접 리뷰하며 어떤 부분이 개선이 필요한지 확인 → 개선 지점을 evaluation metric으로 정량화.
- Data(Knowledge): 지식 저장소의 효율적 구축 & 검색 필요.
-
- Tool calling: Agent의 접근/사용 범위를 확장하기 위한 tool 연동.
- 도구마다 다른 API 명세를 어떻게 LLM에 주입할 것인가? 도구의 역할 입력 방법?
- 사용 가능한 tool들이 늘어날수록 의도하지 않은 결과 발생 (context length 제한, tool 설명과 실제 명령의 길이) → 도구 설명 단계와 실제 도구 사용 단계 분리.
- Tool calling: Agent의 접근/사용 범위를 확장하기 위한 tool 연동.
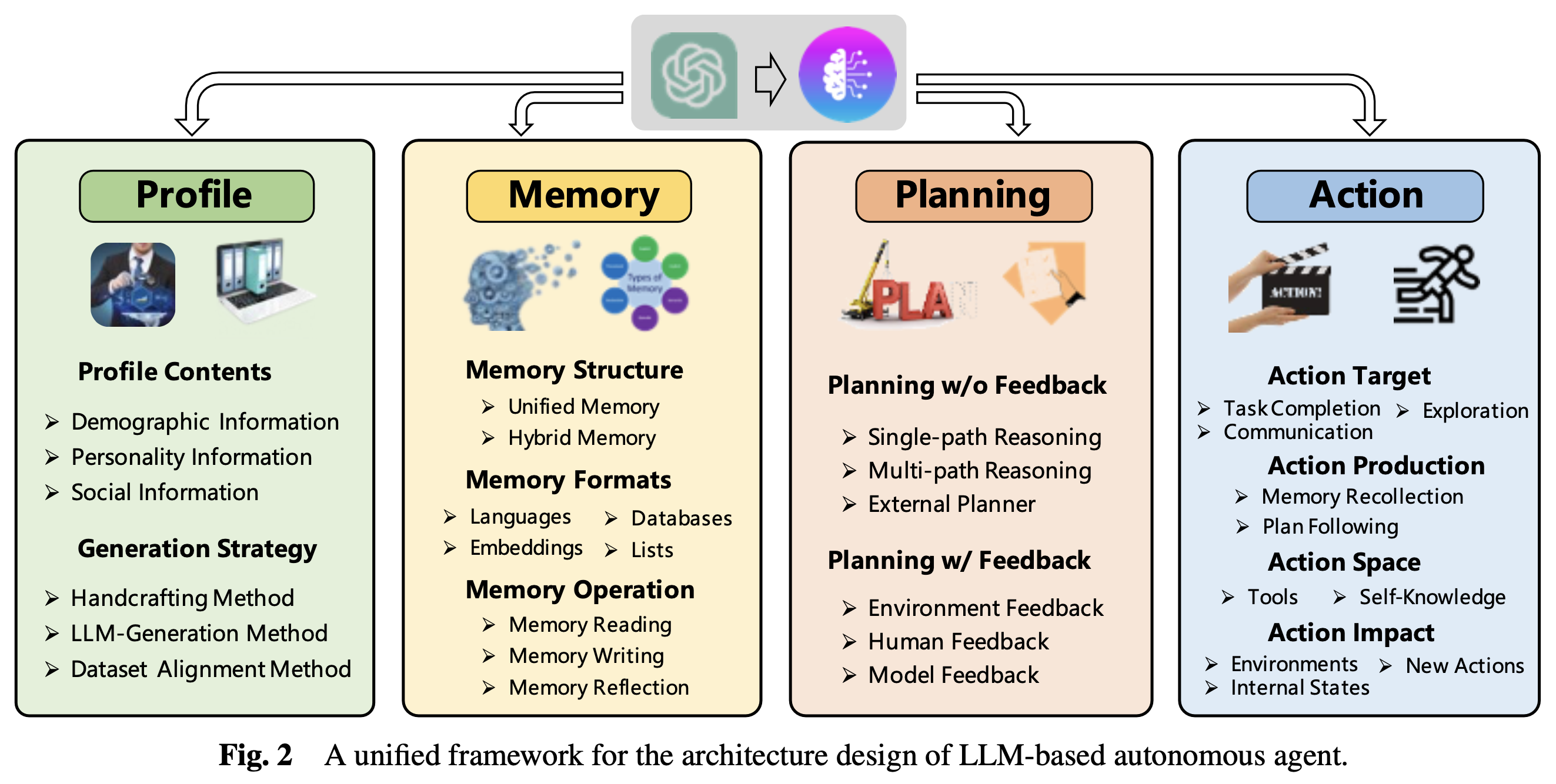
Profile 모듈: Agent의 역할을 정의하는 모듈.
Memory 모듈: 미래 행동을 안내하기 위해 환경에서 얻은 정보를 저장하는 모듈.
Planning 모듈: 복잡한 작업을 더 간단한 하위 작업으로 분해하는 모듈.
Action 모듈: Agent의 결정을 특정 결과로 translate하는 모듈.
일반적인 AI(LLM) Agent 프레임워크 단계
[1단계] 목표 초기화
[2단계] 작업 생성: 메모리에 마지막으로 완료한 작업 X개가 있는지 확인한 다음, 목표와 최근에 완료한 작업의 컨텍스트를 사용하여 새 작업 목록을 생성.
[3단계] 작업 실행
[4단계] 메모리 저장: 작업과 실행 결과를 데이터 베이스에 저장.
[5단계] 피드백 수집: 완료된 작업에 대한 피드백을 외부 데이터 또는 에이전트간의 내부 대화 형식으로 수집. 이 피드백은 적응형 프로세스 루프의 다음 반복을 알리는 데 사용됨.
[6단계] 새 작업 생성: 수집된 피드백과 내부 대화를 기반으로 새로운 작업을 생성.
[7단계] 작업 우선순위 지정: 작업 목록의 목표를 검토하고 마지막으로 완료된 작업을 확인하여 작업 목록의 우선순위를 다시 지정.
[8단계] 작업 선택: 우선순위가 지정된 목록에서 최상위 작업을 선택하고 3단계(작업 실행)를 수행.
[9단계] 반복: 이후 4단계부터 8단계까지를 연속적으로 반복하여 새로운 정보, 피드백 및 변화하는 요구 사항에 따라 시스템이 적응하고 진화할 수 있도록 함.
References
- https://www.kaggle.com/whitepaper-agents
- https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-llm-agents
'Research & Study Notes' 카테고리의 다른 글
| AI Agent Protocols(feat. MCP, A2A) (3) | 2025.07.02 |
|---|---|
| What are AI(LLM) Agents? (0) | 2025.07.01 |
| Medical-LLM Evaluation: Methods and Metrics (0) | 2025.04.17 |
| Comparison of Keyword Extraction Methods (0) | 2025.01.22 |
| 처음부터 RAG pipeline 구현하기 - (2) (1) | 2024.12.17 |