![]()
2024년에 arXiv에 제출된 'The landscape of emerging AI agent architectures for reasoning, planning, and tool calling: a survey' 논문을 바탕으로 작성된 리뷰입니다. (Masterman, T., Besen, S., Sawtell, M., & Chao, A.) AI Agent ArchitectureSingle Agent ArchitectureMulti Agent Architecture최근 실제 문제를 해결하는 Agent에 대해 많은 연구들이 이루어지고 있다.ex) SWE-Agent, AutoCodeRover, Octopus-v2 + Agent를 위한 프레임워크(Tiger, NPi, CopilotKit)Survey의 목적..
![]()
응급실 환경에 적용할 수 있는, LLM 기반의 환자 및 보호자 친화적 응급 의료 서비스 제공을 위한 모델을 개발하던 중, 의료 LLM의 평가 방법과 지표들 정리의 필요성을 느꼈다. LLM의 평가 방법은 기존 모델들의 평가 방법과 다르게 명확하게 정해져있지 않다. 그 이유는 여러 가지가 있지만, 언어 자체의 복잡하고 모호한 특성, 응답 품질의 주관성, 전통적인 정량 지표의 한계, 추론 능력 측정의 어려움 등이 있다. 특히, 의료 LLM의 경우 답변의 정확도에 따라 생명을 좌우하기 때문에 정확한 평가가 이루어져야 하고, 평가자의 전문성이 요구되며, 윤리적/법적 책임 문제, 의학적 근거의 최신성도 고려해야하기 때문에 더욱 복잡하고 어렵다. 효율적인 평가 방식을 제안할 수 있도록, 의료 LLM 평가와 관련된 연..
![]()
2023년에 EMNLP에 게재된 'Query rewriting for retrieval-augmented large language models' 논문을 바탕으로 작성된 리뷰입니다. (Ma, X., Gong, Y., He, P., Zhao, H., and Duan, N.) AbstractRetrieve-then-Read 파이프라인에서 LLM은 강력한 black-box reader로 활용된다.Retrieve-then-Read 프레임워크: 일반적인 검색 증강 방식으로, query와 관련된 문서를 외부에서 검색해온 후 LLM이 query & 문서를 입력받아 답변 예측하는 방식대부분의 LLM이 추론 API를 통해서만 접근 가능하므로, 파이프라인 내에서 black-box의 형태로 “frozen reader”의 역..
![]()
2020년에 Frontiers of medicine(Article)에 게재된'Deep learning in digital pathology image analysis: a survey' 논문을 바탕으로 작성된 리뷰입니다.(Shujian Deng, Xin Zhang, Wen Yan, Eric I-Chao Chang, Yubo Fan, Maode Lai, and Yan Xu) 전통적인 방법론: Hand-crafted domain-specific features / disease-related tissue changes by extracting mathematical features(morphological, textural, structural, fractal)딥러닝: Representation learni..
![]()
연구개발동아리에서 '복잡한 쿼리에서의 검색 성능 저하 문제'를 해결하기 위한 새로운 RAG 방식을 팀원들과 함께 고안해보고있다. 우리 팀이 Query에서 키워드를 추출할 때 사용한 기본 알고리즘은 그래프 기반의 랭킹 알고리즘인 TextRank이다. 우리의 방식을 적용했을 때의 성능과 다른 키워드 추출 알고리즘들을 적용했을 때의 성능을 비교하기 위해 4가지 방법들(NLTK, SpaCy, Rake, Yake)에 대해 알아보았다. (단, Encoder 계열 모델은 제외하였다.)1. NLTKNatural Language ToolKit텍스트 처리를 위한 다양한 모듈을 제공. TF-IDF 및 TextRank 기반 키워드 추출을 위한 루틴이 포함되어 있음.텍스트 전처리토큰화품사 태깅 (Part-of-Speech Ta..
![]()
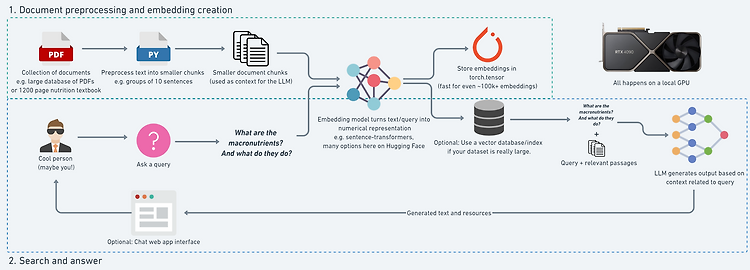
저번 게시글 '처음부터 RAG pipeline 구현하기 - (1)'은 위의 그림에서 [1] 문서 전처리 및 Embedding 생성 단계 에 대해서 다뤄봤다면, 이번 게시글은 Retriever, Augmentation, Generation 과정을 구체적으로 다뤄볼 예정이다.RAG - Search and AnswerRetrieval: 주어진 query와 관련된 resource 가져오기Augmentation: 관련 resource를 prompt에 입력하여, LLM이 해당 정보를 기반으로 텍스트 생성Generation: 검색된 resource를 활용하여 강화(증강)된 응답 생성Similarity searchImport embeddings & embedding modelimport randomimport torc..
![]()
RAG(Retrieval Augmented Generation)를 공부하면서 RAG pipeline을 직접 처음부터 구현해보고싶다는 생각을 하게 되었고, 적은 자원으로도 pipeline의 전 과정을 실행해볼 수 있는 오픈 소스를 발견하였다. 5GB+ VRAM을 가진 NVIDIA GPU만 있다면 local 환경에서도 실행할 수 있다. - 링크: https://github.com/mrdbourke/simple-local-rag - Setting: Python 3.11, CUDA 12.1, NVIDIA RTX 4090 + Windows 11 RAG 프로젝트 목표: NutriChat를 build하는 것사람이 Nutrition Textbook 1200 페이지 분량의 PDF 버전에 대해 query 허용LLM이 t..
![]()
※ 본 내용은 도서 '파이썬 텍스트 마이닝 완벽 가이드(박상언, 강주영, 정석찬 지음. 위키북스)'를 참고하여 만든 학교 강의 실습 자료를 바탕으로 하였습니다. Hugging Face딥러닝 모델과 자연어처리(NLP) 기술을 개발하고 공유하는 회사다양한 딥러닝 프레임워크를 지원하는 라이브러리와 도구 제공Transformers 라이브러리자연어처리(NLP), 컴퓨터 비전, 오디오 및 음성 처리 작업에 대한 사전 훈련된 최첨단 모델 라이브러리컴퓨터 비전 작업을 위한 현대적인 합성곱 신경망과 같은 트랜스포머가 아닌 모델도 포함Tokenizers, Datasets와 같은 라이브러리를 추가로 제공하여 task를 수행하기 위한 tokenizer, dataset을 손쉽게 다운로드 받아 사용Pipeline() 함수Tran..
![]()
2023년에 ACM Transactions on Information Systems에 게재된'An Analysis of Fusion Functions for Hybrid Retrieval' 논문을 바탕으로 작성된 리뷰입니다.(Bruch, Sebastian, Siyu Gai, and Amir Ingber)IntroductionRetrieval: multi-stage ranking system의 첫번째 단계목표: 거대한 문서 집합 $\mathcal{D}$에서 주어진 query $q$와 가장 관련성이 높은 top-$k$개의 문서들을 찾는 것(1) Query와 Document 사이의 관련도를 어떻게 측정할 것인가? → 본 논문에서 다루는 주제(2) 주어진 유사도 metric에 따라 top-$k$개의 문서들을 어..