
2022년에 ACL에서 발표된 UNIPELT: A Unified Framework for Parameter-Efficient Language Model Tuning
논문을 바탕으로 작성된 리뷰입니다. (Yuning Mao, Lambert Mathias, Rui Hou, Amjad Almahairi, Hao Ma, Jiawei Han, Wen-tau Yih and Madian Khabsa)
Abstract
최근 Parameter-efficient language model tuning(PELT)의 영향으로 적은 trainable parameter들로도, 특히 training data가 제한된 상황에서 좋은 성능을 낼 수 있게 되었다.
문제점 : PELT 방법이 다르다면 같은 task에 대해서도 다르게 적용되어 특정 task에 가장 적절한 방법을 선택하기 어렵게 만든다.
모델 다양성과 모델 선택의 어려움을 고려하여, 다양한 PELT 방법을 하위 모듈로 통합하고, gating mechanism을 통해 현재 data 또는 task 설정에 가장 적합한 방법을 활성화하는 방법을 학습하는 통합 프레임워크인 UNIPELT를 제안한다.
- GLUE benchmark에서 UNIPELT는 다양한 setup에서의 fine-tuning 성능을 능가하고 최고의 개별 PELT 방법과 비교하여 일관되게 1~4%의 gain을 달성한다.
- 또한, UNIPELT는 일반적으로 각 task에 대해 개별적으로 사용되는 모든 하위 모듈의 최상의 성능을 취하는 상한을 초과하는데, 이는 여러 PELT 방법의 혼합이 단일 방법보다 본질적으로 더 효과적일 수 있음을 나타낸다.
Introduction
Pre-trained Language Models(PLMs)의 크기가 커지면서 모델 parameter의 분리된 replica들이 단일 task 당 수정되는 기존의 fine-tuning을 수행하는 것이 어려워졌다.
→ 적은 trainable parameter들로도 PLM을 효율적으로 tuning할 수 있는 PELT 연구들이 진행되고있다.
→ 몇몇 PELT 방법들은 training data가 제한된 상황일 때, 특정 task들에 대해 fine-tuning한 것보다 overfitting의 위험을 감소시킨다는 점에서 더욱 효율적이다.
다른 PELT 방법들은 그 특성에 따라 같은 task여도 다르게 적용되어 빠르게 증가하는 PELT 방법들 중 특정 task에 가장 적절한 방법을 선택하기 어렵게 만든다.
▶ PELT 방법의 다양한 성능과 최적의 방법을 선택하는 비용을 고려하여, 서로 다른 PELT 방법을 하위 모듈로 통합하고, 현재 data 또는 task setup에 가장 적합한 하위 모듈 조합을 동적으로 활성화하는 방법을 학습하는 UNIPELT라는 이름의 통합 PELT 프레임워크를 제안한다.
- 모델을 선택할 필요없이 다른 setup에 대해서 더 나은 성능이 유지된다.
- 각 하위 모듈의 activation은 gating mechanism에 의해 조정되는데, 이는 주어진 task에 긍정적으로 기여하는 하위 모듈에 더 높은 가중치를 부여하도록 학습시킨다.
- 각 하위 모듈의 parameter 수는 일반적으로 적기 때문에 여러 방법을 합치는 것은 모델 효율성 측면에서 무시가능하다.
대표적인 PELT 방법들의 후보로 (1) adapter, (2) prefix-tuning, (3) LoRA, (4) BitFit 를 선택하였다.
각 PELT 방법들의 특성 & UNIPELT에서 다양한 setup에 따른 효율성을 실험하였다. GLUE benchmark에 대한 실험 - 32 setup(8 tasks * 4 data sizes) & 1000+ runs
→ UNIPELT는 각각의 PELT 방법만 사용하는 것보다 효율적이고 강력하다는 것을 보여주었다.
- 특히, UNIPELT는 통합한 최고의 하위 모듈을 일관되게 1~4 points 개선하고 fine-tuning 성능까지 능가하여 다양한 setup에서 GLUE benchmark에서 최고의 평균 성능을 달성한다.
- 또한 UNIPELT는 하위 모듈을 개별적으로 사용한 성능의 상한선을 뛰어넘어 다른 setup들에 대해 최적의 성능을 보여주는데, 이는 PLM 아키텍쳐의 다른 부분들을 포함한 PELT 방법들의 혼합이 효율적이라는 것을 보여준다.
Contributions
(1) 대표적인 PELT 방법에 대한 종합적인 연구를 수행하고 성능 및 특성 측면에서 차이점과 공통점을 검토한다.
(2) 기존 방법들을 하위 모듈로 통합하고, 주어진 task에 적합한 하위 모듈을 활성화하는 방법을 자동으로 학습할 수 있는 통합된 PELT 프레임워크를 제안한다.
(3) 제안한 프레임워크는 fine-tuning 및 개별적인 PELT 방법들과 비교하여 더 나은 평균 성능을 달성하였고, 모델 효율성에서 무시할 수 있는 loss와 함께 우수한 효율성과 견고성을 보여준다.
Preliminaries

- 기존의 PELT 방법을 하위 모듈로 포함시키고, gating mechanism을 활용하여 조정한다.
- 다른 하위 모듈의 조합은 다른 sample들로 활성화될 수 있다.

PELT Methods without Additional Parameters
PLM은 추가 매개변수 없이 top layer 또는 prediction head만 fine-tuning 되도록 하는 feature extractor로 사용될 수 있다.
→ 이러한 fine-tuning 접근은 일반적으로 모든 parameter들을 fine-tuning하는 것보다 나쁜 성능을 보인다.
BitFit : PLM의 bias terms들만 tuning하여 특정 task들에 대해서만 fine-tuning한 결과와 비교될만한 성능을 보인다.
PELT Methods with Additional Parameters
전체 PLM을 고정하고 적은 수의, 새로운 trainable parameter들을 사용하는 방법으로 adapter 계열, prefix-tuning 계열, 그 외의 추가적인 방법(ex. LoRA)들이 있다.
(1) Adapter
- PLM의 각 Transformer layer에서 FFN 이후에 trainable bottleneck layer을 추가한다. (직렬 구조)
- bottleneck layer : (down + up) projection쌍으로 구성되어있고, token hidden states의 크기를 줄이고 원래대로 복원된다.
- bottleneck layer의 output
- ($D_{hidden}$ : hidden size, $D_{mid}$ : bottleneck size, $h_{FN}$ : residual connection&layer normalization 이후의 FFN output)
- $\phi$ : non-linear activation function
- bias : brevity를 위해 생략
- 학습 parameter 수 변화 : $d^2$ → $2md (m <<d)$

$h$ ← $h + f(hW_{down})W_{up}$
- 이후의 연구는 adapter를 multi-lingual&multi-task로 확장하거나, vanilla adapter를 대체하는 역할로 UNIPELT에 쉽게 통합할 수 있는 trainable parameter의 수를 더 줄인다.

(2) Prefix-tuning
- 각 Transformer layer의 multi-head attention input으로 넣는 task-specific trainable vector들의 수(prefix length)를 조절하여, 원래 token들이 가상의 token들인 것처럼 보이게 한다.
- Prefix를 삽입(input vector, attention key, query)하고 Prefix만 학습을 진행한다. (prefix는 가상의 token이라고 가정)
- tuning 과정 ($L$ : prefix length, $L_0$ : original sequence length)
- (1) Linear projections($W_Q, W_K, W_V$)를 통해 Transformer layer의 input$(\in \mathbb{R}^{D_{hidden}\times L_0})$
을 $Q, K, V$로 변형한다. - (2) Prefix matrix $P_K, P_V (\in \mathbb{R}^{D_{hidden}\times L})$
를 $K, V$인 것처럼 만든다.
- (1) Linear projections($W_Q, W_K, W_V$)를 통해 Transformer layer의 input$(\in \mathbb{R}^{D_{hidden}\times L_0})$
- optimization → prefix matrix $P$ 가 FFN에 의해 reparameterized된 결과 : $P'$

이 network의 parameter들은 training 이후에 제거되어도 되고, $2N_{layer}$ prefix matrix가 필요하다. ($N_{layer}$ : Transformer layer의 수)
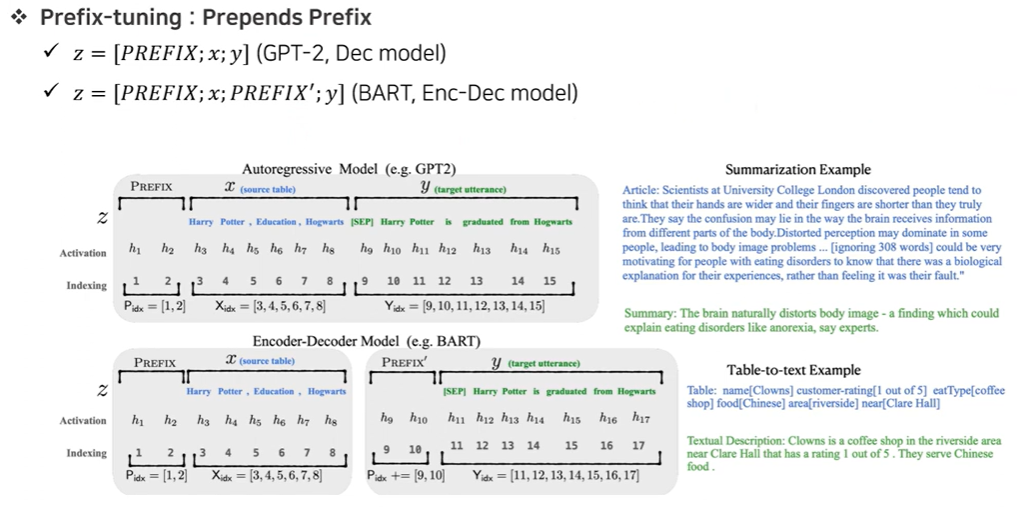
- NLG에 의해 원래 평가되었고, NLU task에 대해서도 adapt시켰다.
- prompt-tuning : 1st layer의 prefix를 제한하여 task-specific parameter들을 줄였다.
Prefix-tuning(Prompt-tuning) ≠ prompt-based fine-tuning methods
- 차이점
- prompt는 학습 과정에서 변하지 않지만 prefix-tuning에서는 prefix만 학습한다.
- prompt는 모델 input에만 들어가지만 prefix는 attention module에도 들어갈 수 있다.
- prompt는 잘 학습된 prompt를 삽입하지만 prefix는 가상의 token을 넣는다.
(3) Additive methods
- fine-tuning 이후의 모델 parameter들을 pre-trained parameters와 task-specific differences들의 추가 사항으로 생각한다.
- $\theta_{task} = \theta_{pre-trained} + \delta_{task}$
- $\theta_{pre-trained}$은 고정되어있고, $\delta_{task}$에 해당하는 새 모델 parameter들이 위에 더해진다.
- $\delta_{task}$를 파라미터화할 수 있는 방법들은 다양한데, LoRA도 포함되어있다. + diff pruning, side-tuning
- LoRA는 trainable low-rank matrix들을 사용하였는데, 이 matrix들을 multi-head attention에서 원래 matrix와 결합한다. (분해된 matrix들만 학습)
- $W_{down},W_{up}$이 $W_Q, W_V$를 따라 query projection과 value projection에 더해진다.($\alpha$ : task-specific 차이를 scaling하기 위한 고정된 스칼라 hyperparameter)


Unifying PELT Methods
Task Formulation
거대한 PLM은 computational, storage cost를 고려했을 때 바로 fine-tuning할 수 없다.
trainable parameters의 list : ${m_i }$ (m들의 절댓값의 합은 PLM의 size보다 작아야 한다.)
▶ 다양한 조건들(method, task, data)을 조합한 상황에서 다른 하위 모듈들을 동적으로 활성화시킬 수 있는, ${m_i }$를 하위 모듈로 통합한 PELT 프레임워크를 설계하자!
Proposed Method
모든 조건에 대해서 우수한 방법론은 없다. 각각의 task마다 최고의 성능을 내는 PELT 방법이 다르다.(ex. prefix-tuning은 training data에 상관없이 natural language inference task에서 좋은 성능을 보인다.)
→ 각각을 실험하는 것보다 unified framework 제안
Adapter, Prefix-tuning, LoRA는 PLM의 서로 다른 부분에 동시에 존재할 수 있고, module간 간섭이 없다!
▶ Task에 가장 적합한 PELT 방법을 찾기 위해 모든 방법들에 대한 조사를 진행하였고, Gating mechanism을 활용하여 통합된 프레임워크를 제안하였다.
- UNIPELT는 현재 task 또는 특정한 data sample에 가장 적합한 하위 모듈을 activate
- UNIPELT는 각 task에서 모든 하위 모듈들을 개별적으로 사용했을 때의 최고의 성능보다 더 좋은 성능을 보인다.
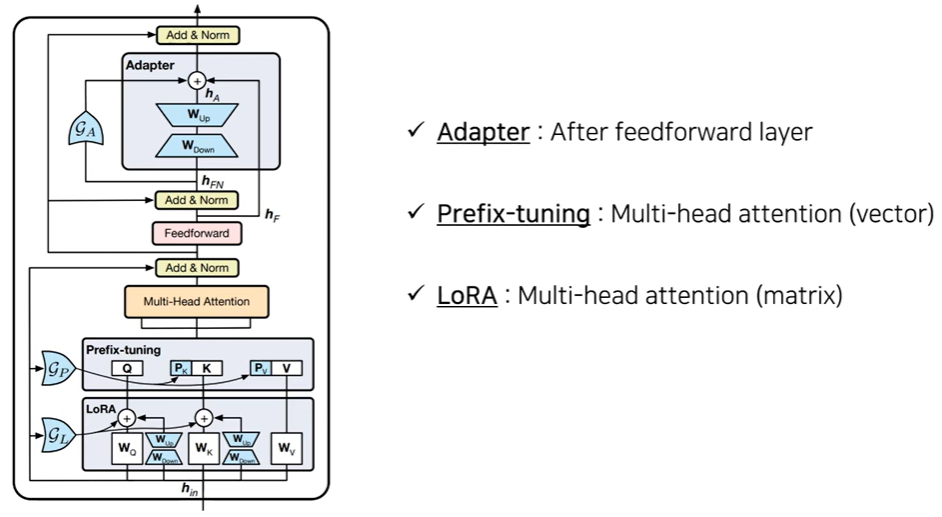
Gating mechanism : PELT 하위 모듈의 importance를 산출하는데 사용하는 방법으로 scaling의 역할을 한다고 볼 수 있다.
- trainable gate를 모든 transformer layer의 각 하위 모듈 ${m_i} \in {A,P,L}$ 에 추가한다.
- (0,1)로 mapping하기 위해 sigmoid 함수를 사용한다.
self.scaling = torch.sigmoid(self.lora_gate(x))
- adapter : FFN과 adapter 하위 모듈 사이에 adapter input을 더하는 residual connection 존재. gating function이 input에 의해 adapter의 중요도를 판단한다.
- prefix-tuning : gating function이 prefix vectors($P_K, P_V)$에 적용한다. function값에 따라 prefix의 영향력을 조절한다.
- LoRA : 상수값을 가지는 scaling factor $\alpha$를 이미 가지고 있다.

Experiments
Experiment Setup
1개의 setup 당 (8 tasks * 4 data sizes * 7 methods * 5 runs) → 1,000+ runs
- Low-resource 환경(training data가 제한된 환경) : GLUE dataset을 활용하여 성능 비교 분석
- 각 task마다 training set size K = {100,500,1000} by sampling
- random seed를 바꿔 5회 실험 후 평균과 표준편차 산출
- High-resource 환경 : GLUE dataset을 활용하여 성능 비교 분석 → training set의 모든 data 활용
※ GLUE는 4가지 NLU tasks들을 가지고 있다.
- CoLA : linguistic acceptability
- SST-2 : sentiment analysis
- MRPC, STS-B, QQP : similarity¶phrasing
- MNLI, QNLI, RTE : natural language inference
method에서 bottleneck layer의 dimension이 중요하다.

Analysis of Individual PELT Methods & Analysis of UNIPELT
아래의 표에서 GLUE benchmark에 대한 다양한 training data size에 따른, PELT 조합들의 성능을 확인할 수 있다.

Low-resource setting
- UNIPELT(APL)이 K의 값에 상관없이, 적은 training sample에 대해서도 평균 성능이 제일 높다.
- Adapter
- 다양한 Task, training data size 등의 조건에서 상대적으로 안정적인 성능 기록
- adapter은 low-resource setting에서 fine-tuning하는 것보다 일관되게 높은 성능을 유지하지 못했다. → 각 task마다 hyperparameter을 tuning했기 때문일 것이라고 생각. → 논문의 실험에서는 bottleneck size를 48로 고정하였다.
- 각 Transformer layer에 1개의 adapter만 추가하였다.
- STS-B와 같은 특정 task에서는 UNIPELT를 제외한 타 PELT(prefix-tuning, LoRA)에 비해 높은 성능을 기록하였다.
- CoLA(K = 100) 같은 경우, bottleneck size를 증가시킬 경우 성능이 향상되었다.
- 다양한 Task, training data size 등의 조건에서 상대적으로 안정적인 성능 기록
- Prefix-tuning
- (K = 100, SST-2), (K = 500, QQP) 등의 training data가 제한된 setting에서 상당히 낮은 성능 기록 → prefix length를 증가시켜도 큰 성능 향상이 없었다.
- prefix-tuning(L = 50)은 adapter 또는 UNIPELT(AP)의 4 tasks보다 낮은 성능을 나타낸다.
- 8 task에 대해 prefix-tuning(L = 50)의 평균 성능은 L = 10일 때보다 성능이 조금 더 좋지 않다.
- prefix length가 길면 multi-head attention의 영향으로 training/inference slowdown를 발생시킨다. → trainable parameter의 수가 많다고 더 나은 성능을 보이지 않는다.
- natural language inference 같은 특정 task(RTE, MNLI)에서 타 PELT 대비 높은 성능을 기록하였다. → 강점
- (K = 100, SST-2), (K = 500, QQP) 등의 training data가 제한된 setting에서 상당히 낮은 성능 기록 → prefix length를 증가시켜도 큰 성능 향상이 없었다.

- LoRA
- 특정 setup에서 낮은 성능과 높은 표준편차 기록(ex. STS-B, QQP)
- K = 1000일 때 우수한 성능을 기록하였다. (8 task들 중 4개의 task에 대해 최고 또는 2번째로 성능이 좋음.)
- 모든 task에 최적인 scaling factor($\alpha$)는 존재하지 않고, sclaing factor에 꽤 sensitive → UNIPELT의 gating function의 효과와 유사하여 그 당위성을 입증하였다. scaling factor를 증가시킬수록 더 큰 gradient update가 일어나 빠른 convergence 가능하다.

- BitFit의 경우 대부분의 setting에서 가장 낮은 평균 성능이 나와서 UNIPELT의 하위 모듈에서 제외
High-resource setting
- UNIPELT가 타 PELT보다 높은 평균 성능을 기록하였다. → 풍부한 training data와 향상 가능성을 고려하였을 때도 높은 성능이 유지된다.
- Gating을 제거한 실험(UNIPELT-NoGATE)을 진행하였고, Gating이 있는 경우보다 성능이 낮다는 것을 통해 그 중요성을 입증하였다.

UNIPELT v/s Upper Bound
- 평균 성능을 기준으로 UNIPELT score과 (PELT 방법 중 best score)를 비교한 결과, 대부분의 경우에 UNIPELT(APL, AP)가 높은 성능을 기록하였다.
- PLM의 다른 부분들을 포함한 PELT 방법들의 혼합이 PLM 구조의 제한된 범위만 사용하는 단일 방법보다 더 효율적일 수 있다.

Efficiency of PELT Methods
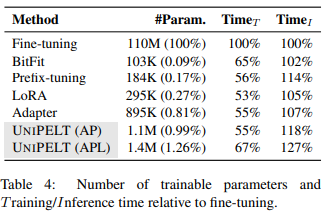
parameter의 수, training/inference 시간 모두 UNIPELT가 타 PELT 대비 낮은 score를 달성하였다.
- parameter의 수 : 여러 PELT 방법을 결합하는 것은 parameter efficiency에 대해 중요하지 않은 정도의 loss를 가진다. UNIPELT는 fine-tuning에 비해 trainable parameter들이 거의 없다. 또한 trainable parameter의 수가 많다고 더 나은 성능을 보이는 것은 아니다.
- training time : parameter efficiency로 인해 fine-tuning 대비 30~50% 더 빠르다.
- inference time : 더 많은 FLOPS(Floating point operation / sec, 절대적 연산량 의미)로 인해 fine-tuning보다 느리다. (inference할 때는 freeze하였던 pre-trained weights도 사용하여 parameter 수 증가)
Related Work
Parameter-Efficient Tuning of PLMs : 새 trainable parameter들이 도입되었는지의 여부에 따라 나눌 수 있다.
- prediction head, bias terms같은 모델 parameter의 일부를 학습하거나 multi-head attention 이전, FF layer 이후와 같은 부분에 task-specific parameter들 도입
Mixture-of-Experts(MoE) : experts(neural networks)의 집합을 유지하면서 1개 이상의 trainable gates가 각 input에 특화된 experts의 조합을 선택한다.
- high-capacity network와 다른 input에 따른 다른 activation part를 포함한다.
- UNIPELT와 차이점
- UNIPELT의 하위 모듈은 MoE의 summation과 다르게 명시적으로 결합되지 않고 암시적으로 sequential order에 따라 결합된다.
- MoE의 experts는 homogenous 또는 identical하지만, UNIPELT는 다양하다.
Conclusion
대표적인 PELT 방법들에 대한 종합적인 연구를 수행하고 다른 PELT 방법들을 하위 모듈로 통합한 프레임워크 UNIPELT를 제안하였다.
이전의 fine-tuning 결과보다 일관되게 뛰어난 성능을 보이고, 각 하위 모듈을 각 task에 개별적으로 사용하였을 때의 최고 성능을 일반적으로 능가하였다.
PELT 방법마다 우수한 성능을 내는 task가 다르다.
이후의 연구에서 보다 다양한 시나리오에서 다양한 PELT 방법들의 차이점을 이해해보고, task-level에서 여러 하위 모듈들의 multi-task setting에 대해서도 실험해볼 예정이다.
- 요약 -
다양한 Parameter-Efficient Language model Tuning(PELT)를 소개하고, 이를 통합한 framework인 ‘UNIPELT’를 제안하였다.
- PELT 방법론(Adapter, Prefix-tuning, LoRA)마다 우수한 성능을 나타내는 Task가 다르다. → GLUE benchmark 이용해 성능 실험
- Attention module에는 Prefix-tuning, LoRA를 적용하였고, FFN에는 Adapter를 적용하였다.
- UNIPELT라는 PELT 방법들을 통합한 프레임워크는 training size에 따른 low/high resource 환경에 상관없이 가장 우수한 performance를 기록하였다.
- Gating mechanism을 활용하여 각 PELT 모듈의 activation 정도를 학습을 통해 효과적으로 조합할 수 있다.
'Paper Review > LLM Fine-tuning' 카테고리의 다른 글
| [Paper Review] LoRA: Low-Rank Adaptation of Large Language Models (2021.06) (1) | 2024.02.12 |
|---|